Reinforcement Learning with Penguins
Time for a personal project! This had nothing to do with classes, I just wanted to learn about Reinforcement Learning. This is a type of machine learning that uses a neural network and trains it in a simulation to produce an AI.
In this project, I set up a simple Unity video game scene where an AI controlled penguin catches fish and brings them back to its baby on the shore.
The whole thing follows a tutorial that can be found here: https://www.immersivelimit.com/tutorials/reinforcement-learning-penguins-part-1-unity-ml-agents Thanks a lot to Adam Kelly for posting it!
It uses a Unity plugin called ML-Agents, which saw its official 1.0 release just a few months ago. The tutorial is even earlier, and comes from version 0.14, so there are a couple minor differences in my code where I migrated to the newest version (release 5, version 1.2). Even as I’m writing this, 1.3 was released today. It’s a fast-growing product!
What is Reinforcement Learning, anyway?
Reinforcement Learning is a type of machine learning that focuses on training a program, usually called an “agent”, to make a series of decisions in a complex environment.
That’s a fairly loose definition of course, there are several ways this can be done. Even the agent doesn’t have to be the same thing. In this example I trained a neural net to make decisions based on some sensory input data, but any program that has an input and output and can learn over time could work.
The basic idea is that the agent is run through a simulation, and gets assigned a score based on the rules of that simulation. This score is the reinforcement, and the agent tries to maximize it.
One important part is that the agent doesn’t know anything ahead of time, none of the task is hard-coded. It simply learns through trial and error. Sometimes this can take a lot of fine tuning of hyperparameters and model structure, but when successful it results in a single program that can perform a complex task without any explicit instructions.
How it works in this example
For this specific example, I taught a penguin AI to catch fish and bring them back to its baby. There’s multiple steps to this, since it has to find and catch a fish, deliver it to the baby, then repeat. To make it even more interesting, the baby has a random position on the shore, the fish can move, and it can only carry one fish at a time.
The reinforcement part of the learning is based on a score. We add 1 to the score any time the penguin catches a fish or feeds a fish to the baby. We also subtract .01 from that score every step of the simulation. This encourages the agent to complete tasks as quickly as possible.
Setting up this score system is a core part of reinforcement learning, since it is the feedback the model is trained on. A common pitfall in reinforcement learning is having a model that learns to maximize its score without actually completing the task it’s supposed to.
Aside from that reinforcement score, we also have to give the agent some senses. It can’t complete the task if it can’t see anything after all! The input for this agent is just 5 sensors that look in front of it. Every few frames each sensor casts a sphere into the game world and reports back if it hits a fish or the baby.
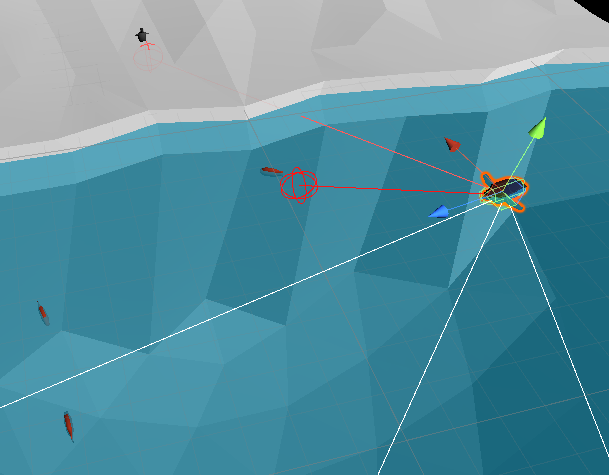
Then, based on this input it outputs some decision which controls the penguin. This simulation uses a very simple control scheme, where the penguin is controlled by only two inputs. The first decides if the penguin moves forward or not (0 or 1), and the second decides if it turns or not (0, 1, or 2, depending on the direction.
One cool thing about this is that by mirroring the control inputs a player would have, it forces the agent to behave in a way that any player could.
So in the end, we input a vector such as [‘nothing’, ‘nothing’, ‘fish’, ‘nothing’, baby’] to the neural net, and get back the controls as another vector [1, 0]. We let the simulation play out, then feed in the reinforcement score and let the model readjust (Back Propagation!) to try and get a higher one.
Let’s train some penguins!
There’s one more important bit to mention about how we train with reinforcement learning. Just like how any human would learn, the model learns faster if it starts with an easier task and gradually moves to more difficult ones.
We do this with ML-Agents by setting up a “curriculum” with different parameters that makes the task more or less difficult. Right at the start, the fish don’t move at all and the penguin just has to get within a certain distance of the baby to feed it. But as the model learns our program automatically advances through the curriculum, so the fish start to move faster, and eventually the penguin actually has to touch the baby instead of just getting close.
And of course, we can speed things up by running the simulation faster than normal and running multiple simulations at a time. In the examples below, we have 8 penguins training at around 2-3x normal speed. Each one is using the same neural network, so this is kind of like training with multiple threads at once.
This first gif is the penguin right when it started learning. Surprisingly, the random initialization of the neural network results in enough movement that the penguin still completes its task, but you can see points where it just moves into a wall instead. (I know, I know, I didn’t set up the scene lighting very well)

This next gif is after 15 minutes of training. By now the fish are moving and the penguin has to get pretty close to the baby. It’s already getting good at performing the task at this point, as you can see the penguin repeatedly going between fish and the baby. There’s still a lot of extra movement where it goes in unnecessary circles though.

Now, after 30 minutes, the model is almost finished training. It’s getting pretty good at catching fish and bringing them back.

In conclusion
The training session hit it’s goal only a few minutes after that last gif. In the end, we have created a simple AI program that performs a multi-step task. All by telling a program to get as high a score as possible and nothing else.

Reinforcement learning like this can create AI programs for a multitude of tasks. It’s easy to see how you could teach a video game AI this way, but it’s also applicable in other ways such as self-driving cars.
And this example only scratches the surface of what’s possible, there are more techniques you can apply to the training process and the model itself. You can have competing AI agents work against each other to try and get a higher score, or you could teach a robot learn to walk just by how it controls its legs. The possibilities are endless, and sometimes quite entertaining.
The Unity project and all code in it are available on my github here: https://github.com/jonDuke/Unity-ML-Penguins